


量化的概念
- 概念:把高位宽(高精度浮点数,大概1E-38 ~ 1E38)所表示的 权值 和 激活值
用更低位宽(比如低精度8比特定点,【0,255】,【-128,127】)来近似表示 - Float32 ---> int8 / uint8
- 优点:
- 定点运算指令比float32运算指令,单位时间能处理更多的数据
- 模型大小可压缩,32bit 权值量化为 8bit 可以减少4倍存储空间
- 有效降低内存带宽,在模型做推理时,量化后的模型会占用更小的带宽
- 便于在线升级,模型更小意味着更加容易传输,之后进行版本更新的时候可以减少网络传输时间
- 支持微处理器,有些微处理器属于8位的,低功耗运行浮点运算速度慢,需要进行8bit量化
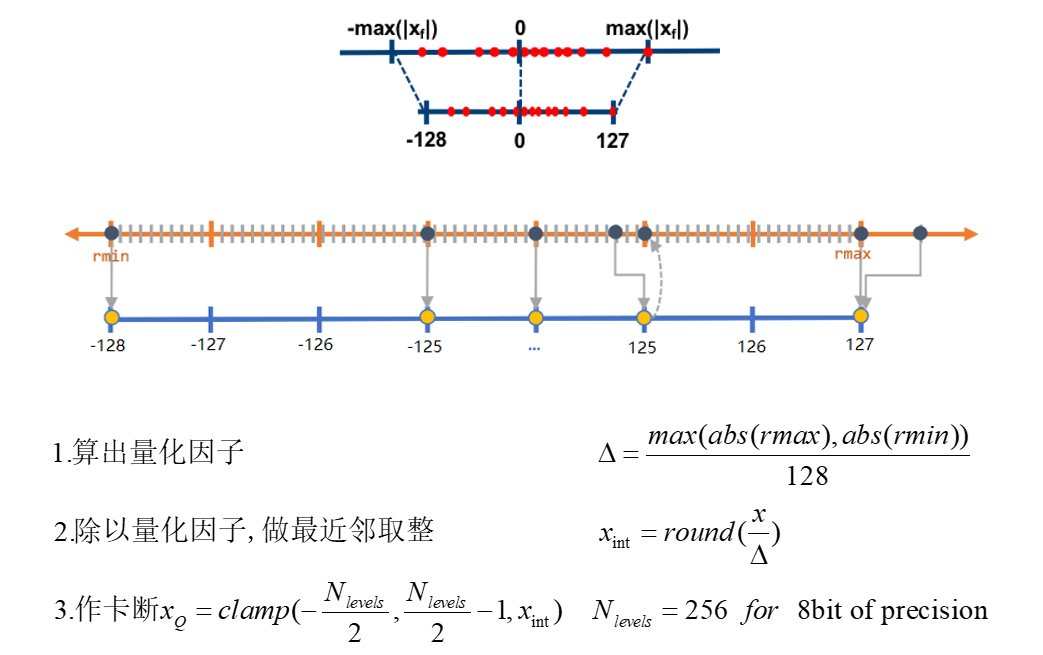
对称&非对称量化
- 对称量化的过程(简易版,其实就是将 float32 给映射到 int8 中):
- 非对称量化的过程
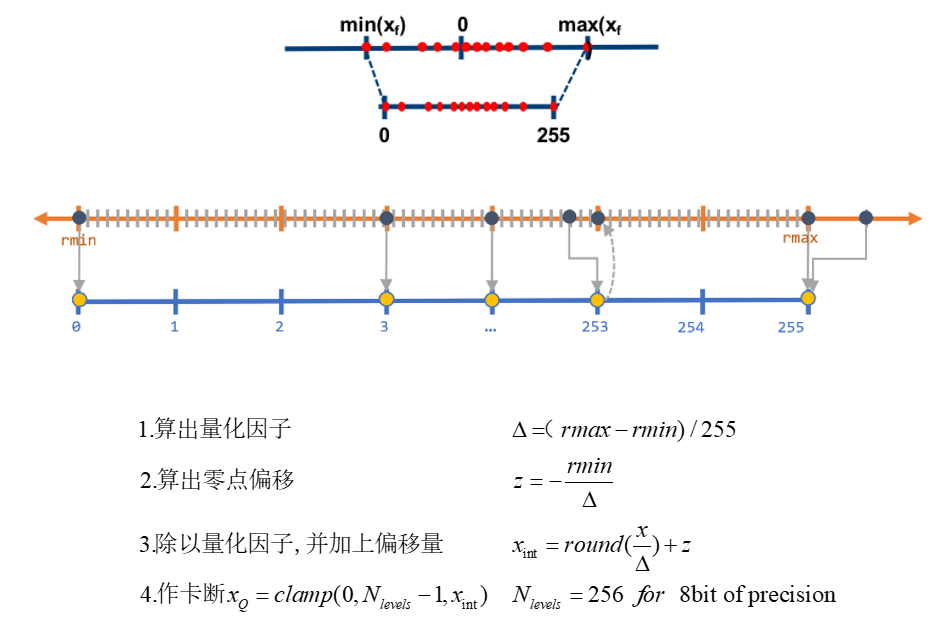
- 为什么要加上偏移量?
- 0 具有特殊含义,如卷积操作中加上的一层padding
- 让映射后区间整体偏移,让rmin对应0
- 为什么要加上偏移量?
TensorRT后量化方法 (设备为GPU时)
- 不饱和的线性量化(如上面提到的直接用rmax算出量化因子),会对导致精度损失较大
- TensorRT 的解决方法
- 激活值做饱和量化,选择合适的阈值
|T| - 权值直接作非饱和量化
如图:
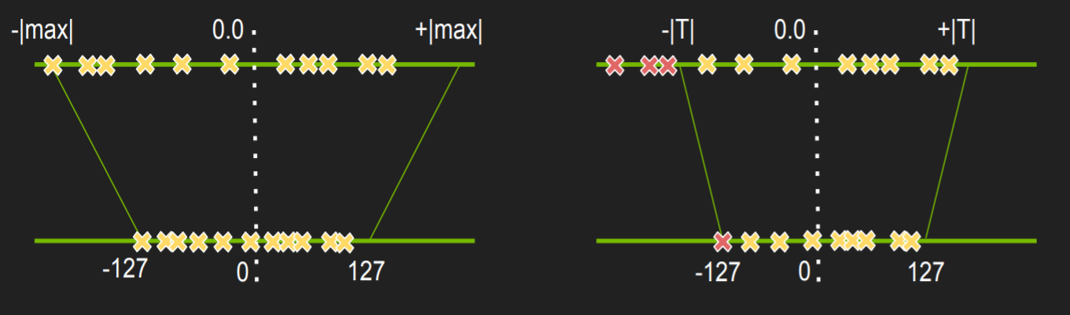
- 直接将超出的
|T|的部分都归为|T|之后,就可以使得 量化后的值
能够均匀的分布在 [-127, 127] 之间 - example ---> 如图:

- 我们可以看到如果将后面的几个稀疏的点作为量化标准的话,其他的值就会被压缩到很小的区间,有很大一部分不相等的部分都被压成了相等的。
- 那么很容易导致量化后的模型精度不达标的问题。
- 激活值做饱和量化,选择合适的阈值
模拟量化
- Forward的过程中模拟量化这个过程,把 权值 和 激活值 量化到 8bit再反量化回有误差的32bit, 训练还是浮点 backward 的时候求得的,梯度 是模拟量化之后的权值的 梯度,用这个梯度去更新量化前的权值。
- 整体流程如下图(具体实现更多为 工程步骤 ):
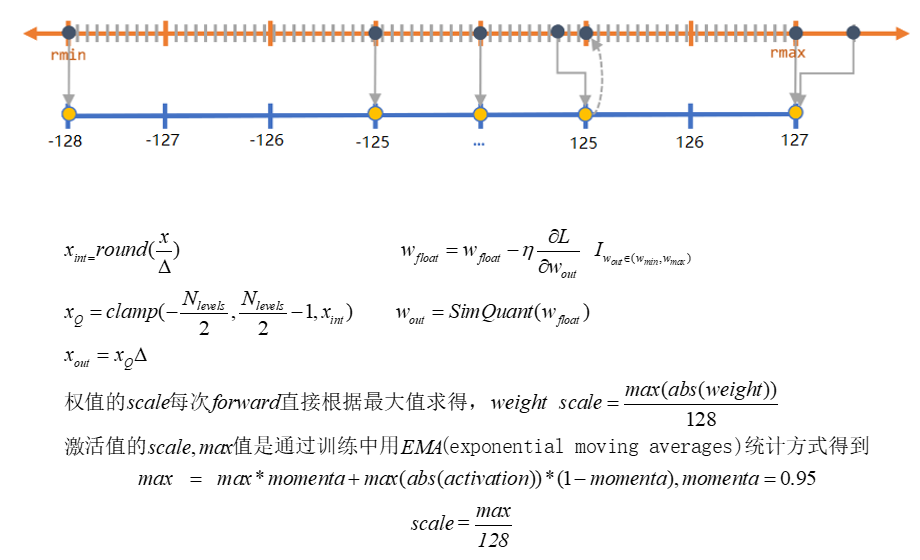
- 如何在训练过程中模拟量化
如图:
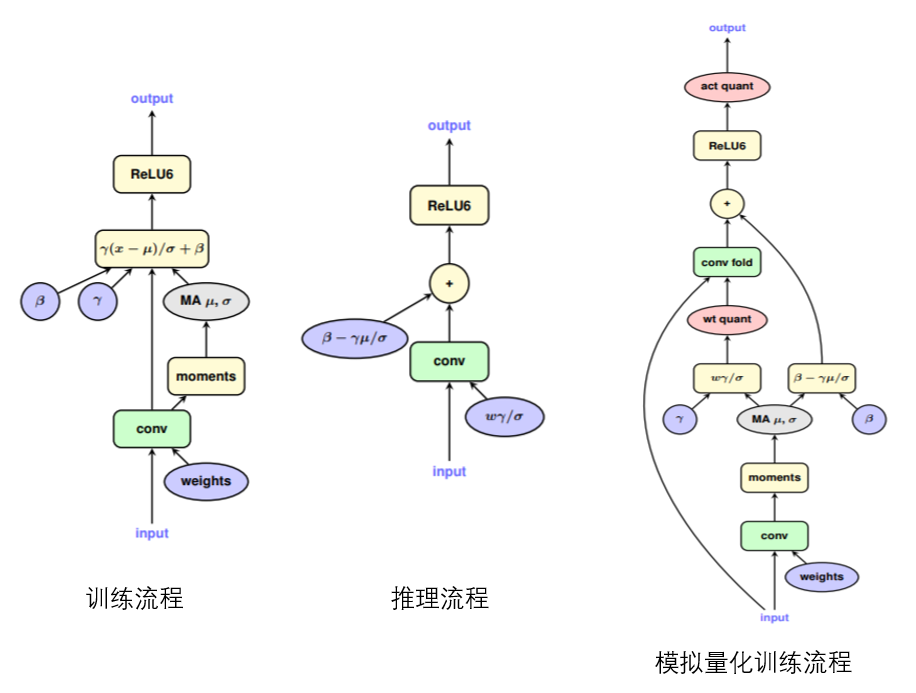
- 我们可以看到模型进行推理的时候,BN层 因为可训练的参数已经固定了,均值和方差这两个数值可以直接被融入卷积计算中去。
- 主要的难点在于如何去识别量化后的参数
推荐参考代码,咱们格灵家的EasyQuant!
虫叔实现的caffe-int8
端侧量化CPU的推理的过程
- 如图:
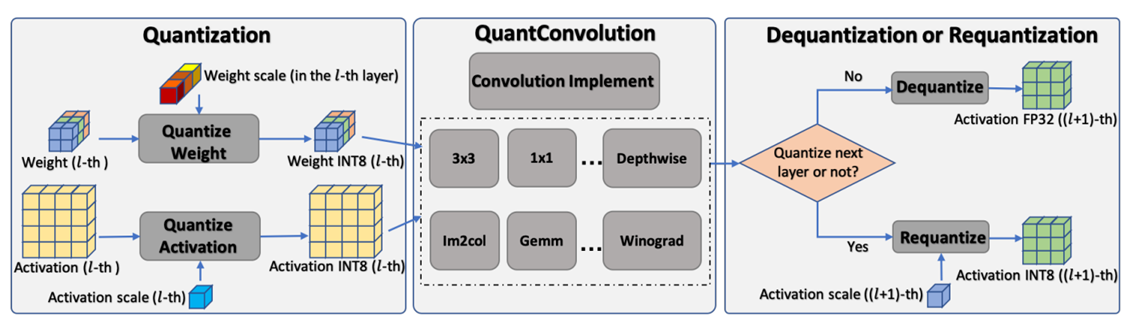
- 图中可以看到分别对权值和激活值进行了量化,分别从浮点的权重和激活值量化到了 INT8大小的权值。
- 端侧真正能通过量化进行推理加速的原因在于,我们能提供定点版本的卷积层(用以适应量化的参数,如ncnn和Tengine这些推理框架提供的)
- 后面根据是否需要接着量化,判断是否要反量化。
- 参考代码:ncnn在arm架构下的后量化操作,我们可以看到很多卷积的定点实现。

