vulkan 的显存管理
-
一个 VkBuffer 对象,多个 offset
- 使用同一块 VkBuffer 存储中间层的特征数据,不同的 blob 使用不同的offset进行区分 。

-
可以在内存架构方面做到零拷贝
- 集成显卡和手机上采用
unified内存架构(统一内存架构),这种架构下,GPU可以直接访问CPU上的主存。利用这种架构上的特性,在GPU计算的时候就不用把 内存上的数据 拷贝到 显存 上,计算完成后也不需要将 显存上的数据 拷贝到 内存。
- 集成显卡和手机上采用

对GPU存储布局的优化
1.[c,h,w] 这种布局不太适合在GPU上做IO:[c, h, w] ---> [c/4, h, w, 4]
- 因为GPU访问和读写显存用的时候更多的是使用 vec4 的类型,ncnn 通过将布局改为**[c/4,h,w,4]**,使得GPU的IO效率得到大幅度提升
-
减少内存带宽的需求
- ncnn 中的 Tensor float数据可以使用半精度
- 在一些不直接支持 fp16 存储的情况下,ncnn 使用 packHalf2x16 和unpackHalf2x16 来模拟 fp16 和 fp32 的转换(这两个函数是 GLSL 内置的函数)
-
更加方便的维护代码
-
ncnn 中创建了一个 GLSL 的宏。
所以写代码的时候可以不用管类型上的事,运行时会自动转换为设备支持的 fp32和 fp16 的对应代码
-
cpu-gpu 混合推理
- 模型中有些层,在没有GPU实现的时候,我们需要自动切换到CPU上去做推理。这就涉及到存储布局相互转换
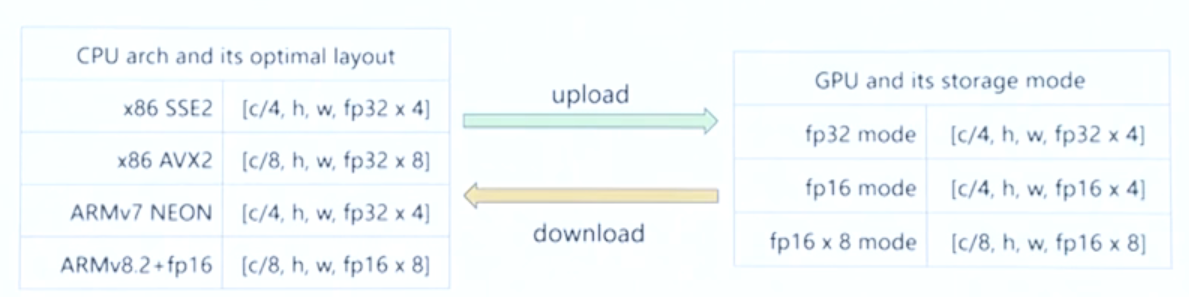
- ncnn 提供了一套pipline,使用一套pipline实现端到端的完成 最佳的布局转换。在独显上也倾向使用 fp16 做上传和下载,能用半精度,也会优先使用。
并行推理
-
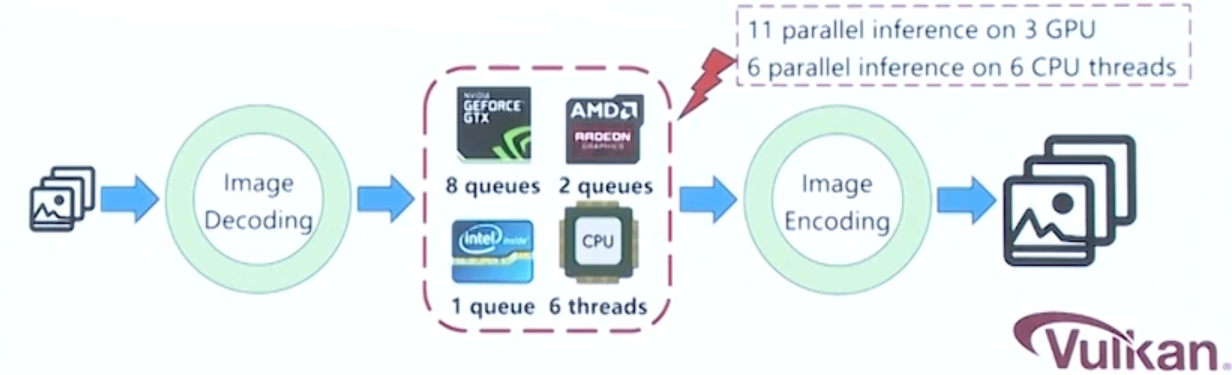
ncnn 在GPU上实现并行推理的方式。
-
Vulkan的api中同一块gpu会暴露多个队列。
例如:nvidia的gpu中有8个队列,那么就可以使用多线程的方式同时在8个队列上提交8个任务。
好处:可以增加GPU的使用率 ,从而提高效率。
-
GLSL->SPIR-V 运行编译
- 原因:有些驱动需要对 GLSL 或者 SPIR-V 的源代码进行特殊的处理,所以只能采用运行时编译
- 好处:不需要在离线时编译多个 SPIR-V 的二进制文件,减少二进制文件的体积。
Swiftshader
- swiftshader项目地址:google在cpu上实现 vulkan驱动 的项目,可以实现在cpu上执行vulkan的代码,可以保证每次代码运行结果都是一致的。
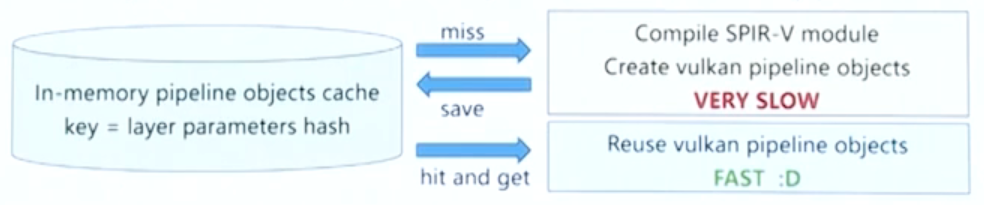
复用 VkPipeline 和相关的 vulkan object
- 模型加载的时候, 特别是第一次加载模型的时候,由于没有离线的cache和优化的手段, pipeline的编译是一个十分耗时的操作。
- 有些模型层的参数(kernal size, stride)是一样的。ncnn 在运行时就将 层的参数 和 vulkan对象 的关系记录下来,当遇到具有相同参数层的时候,就可以直接复用之前创建好的 vulkan对象,这样可以显著降低第一次加载模型的耗时。